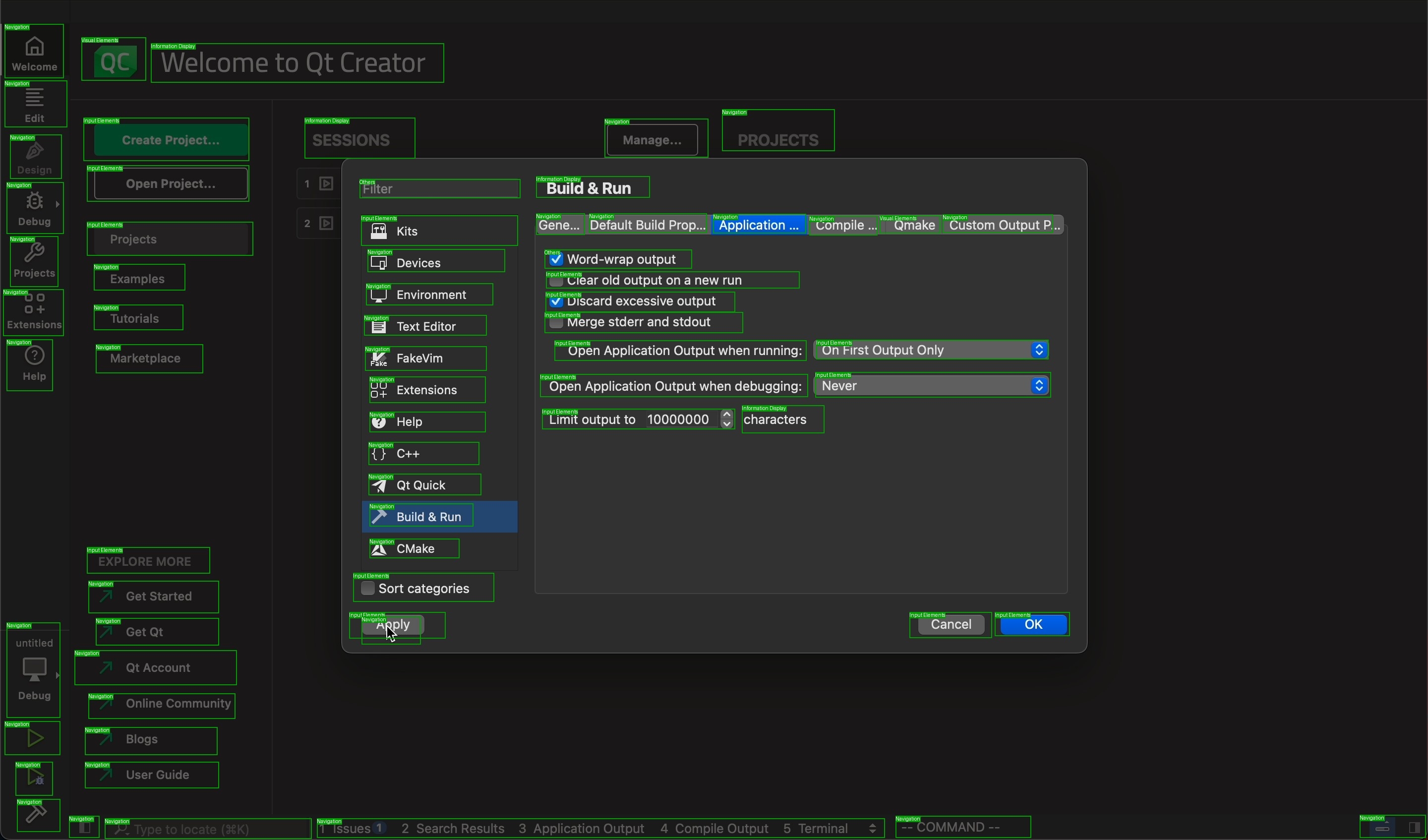
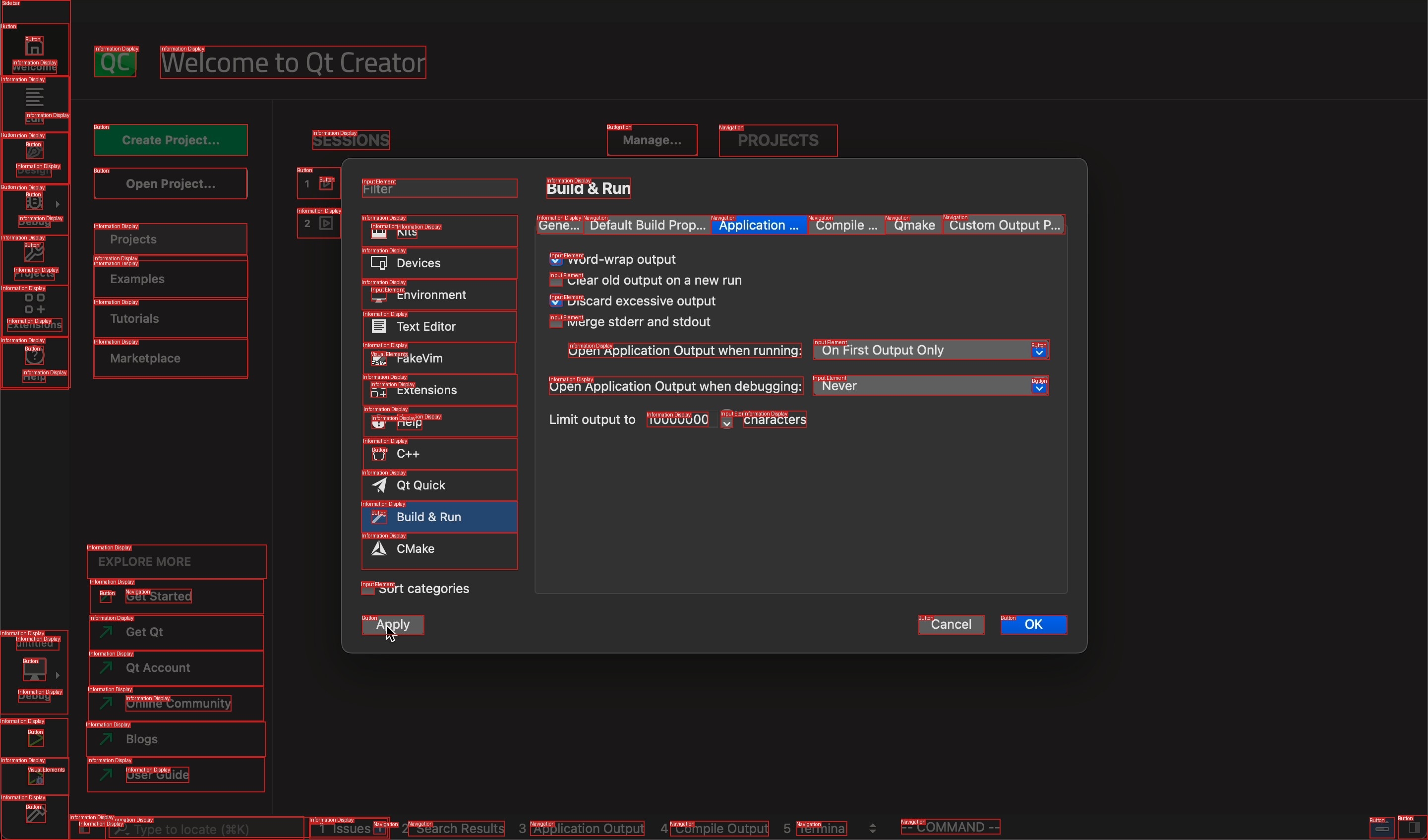
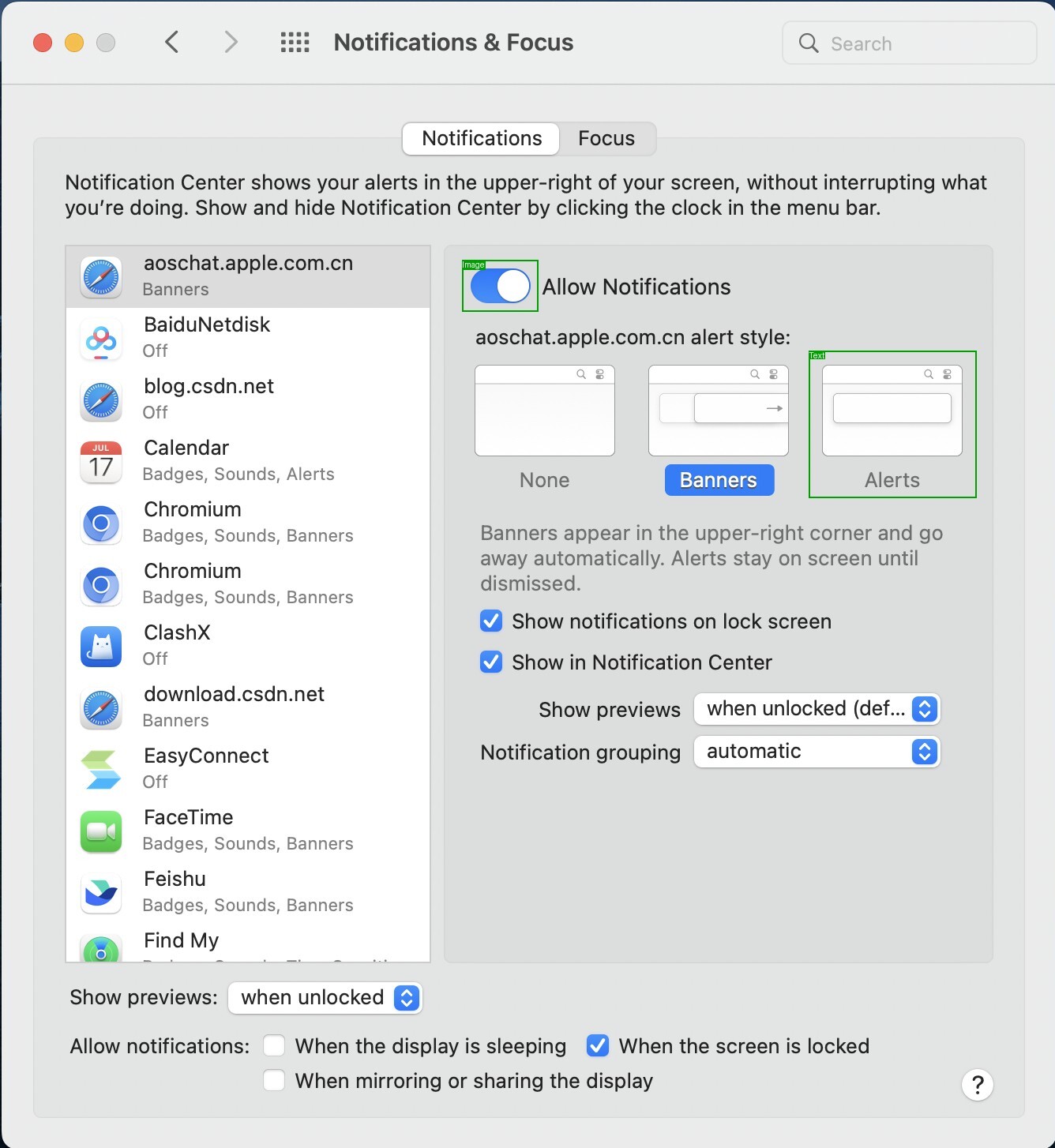
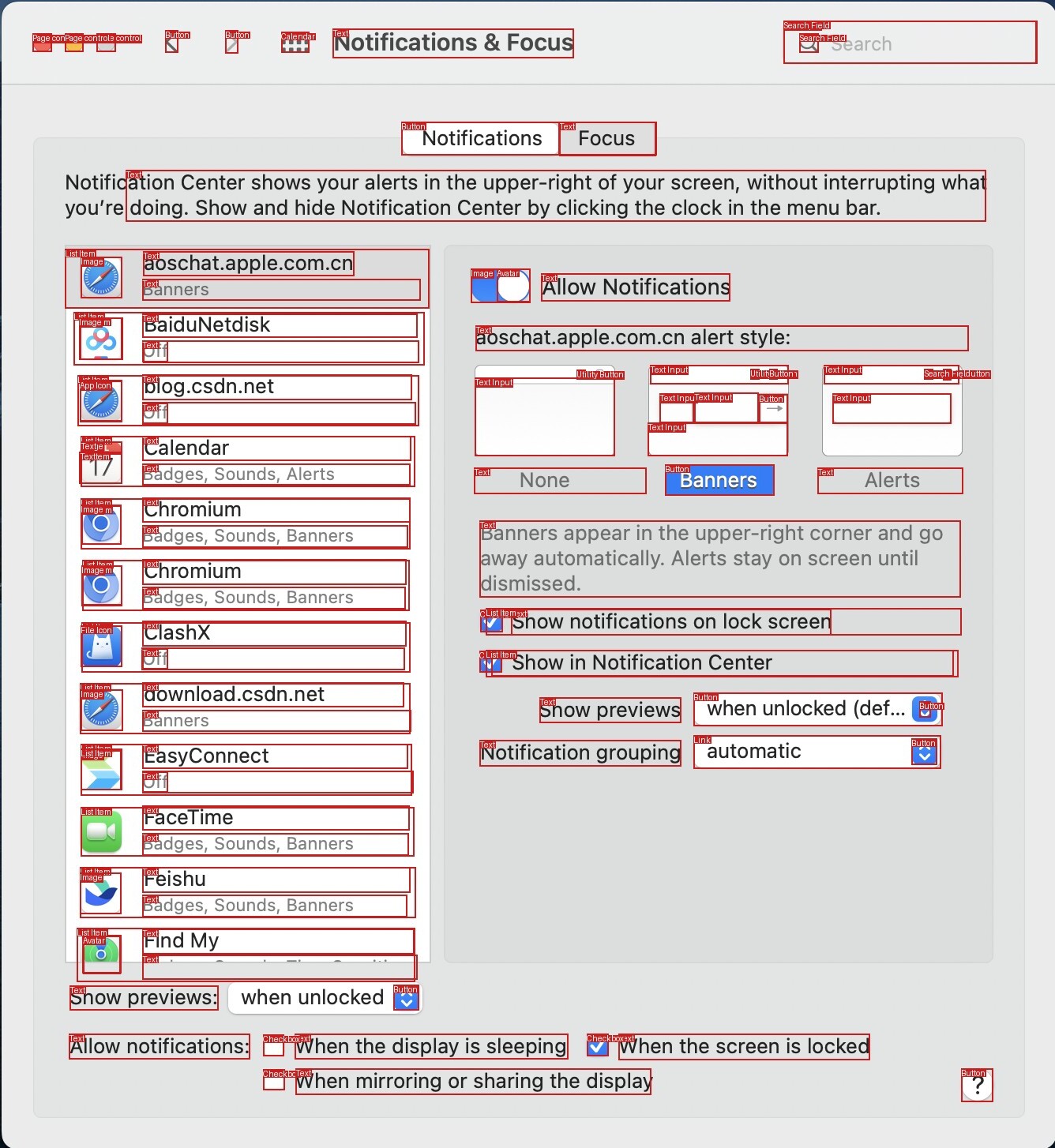
Modern computer-use agents must perceive a screen as a structured state, including what elements are visible, where they are, and what text they contain, before they can reliably ground instructions and act. Yet, most available grounding datasets provide sparse supervision, with insufficient and low-diversity labels that annotate only a small subset of task-relevant elements per screen.
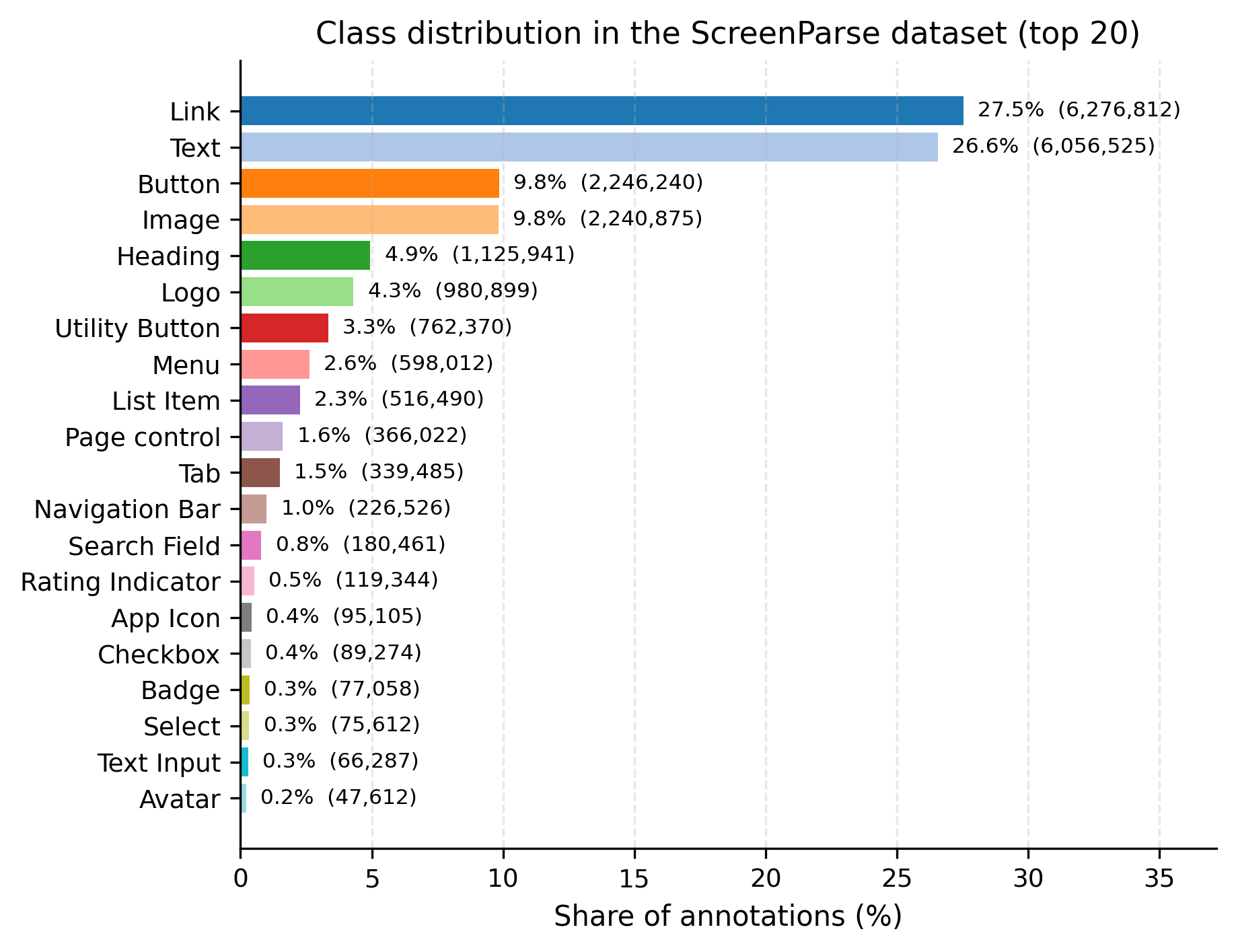
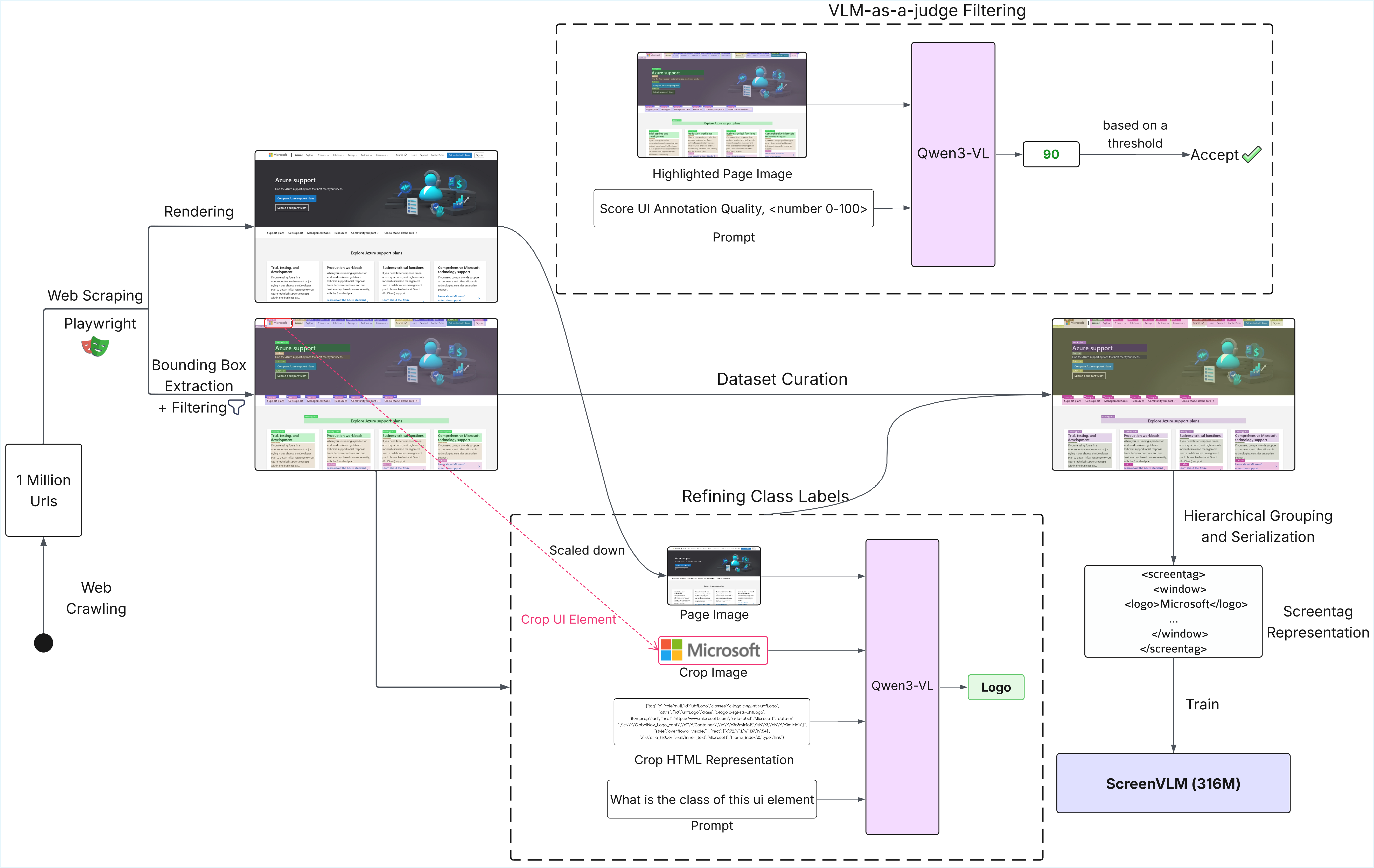
We introduce ScreenParse, a large-scale dataset for complete screen parsing, with dense annotations of all visible UI elements (boxes, 55-class types, and text) across 771K web screenshots (21M elements). ScreenParse is generated by Webshot, an automated, scalable pipeline that renders diverse URLs, extracts annotations, and applies VLM-based relabeling and quality filtering.
Using ScreenParse, we train ScreenVLM, a compact, 316M-parameter vision language model that decodes a structured ScreenTag representation with a structure-aware loss. ScreenVLM substantially outperforms much larger foundation VLMs on dense parsing (e.g., 0.606 vs. 0.294 PageIoU) and shows strong transfer to public benchmarks. Moreover, finetuning foundation VLMs on ScreenParse consistently improves their grounding performance.